 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
May 29, 2026Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
Can Large Language Models Revolutionize Survey Research? Experiments with Disaster Preparedness Responses
May 19, 2026Survey research faces mounting structural challenges: declining response rates, sample bias, block-wise missingness among at-risk respondents, and AI-assisted fraudulent completions in online panels. Large language models (LLMs) have been proposed as a remedy, yet rigorous evaluations across the full survey workflow remain scarce, particularly in disaster contexts where data quality matters most. We present and evaluate a five-stage framework for LLM integration covering questionnaire design, sample selection, pilot testing, missing-data imputation, and post-collection analysis, using the 2024 Hurricane Milton preparedness survey of Florida residents (n=946) as a shared empirical testbed. We introduce a Protection Motivation Theory (PMT)-constrained co-occurrence knowledge graph and develop seven LLM configurations spanning zero-shot inference, retrieval-augmented baselines, and novel theory-informed variants. Our proposed Anchored Marginal Theory-Informed LLM (A-TLM) outperforms all three classical imputation baselines (IPW/MI, MICE+PMM, missForest) on RMSE under disaster-relevant block-wise MNAR conditions (S4 RMSE 1.439 vs. 1.496 for the next-best), while achieving near-zero signed bias (-0.121) where the random-forest imputer produces the largest absolute bias (-0.631). Organizing retrieval around PMT causal structure and integrating all evidence in a single model call outperforms unstructured retrieval and staged sequential inference (MAE 0.993 vs. 1.097 for standard RAG). We document that near-zero aggregate bias can mask opposing subgroup errors and propose subgroup-stratified bias auditing as a reporting standard. A retrieval-constrained knowledge-graph chatbot demonstrates that hallucination is architecturally manageable through grounded refusal.
NarraScore: Bridging Visual Narrative and Musical Dynamics via Hierarchical Affective Control
Feb 12, 2026Synthesizing coherent soundtracks for long-form videos remains a formidable challenge, currently stalled by three critical impediments: computational scalability, temporal coherence, and, most critically, a pervasive semantic blindness to evolving narrative logic. To bridge these gaps, we propose NarraScore, a hierarchical framework predicated on the core insight that emotion serves as a high-density compression of narrative logic. Uniquely, we repurpose frozen Vision-Language Models (VLMs) as continuous affective sensors, distilling high-dimensional visual streams into dense, narrative-aware Valence-Arousal trajectories. Mechanistically, NarraScore employs a Dual-Branch Injection strategy to reconcile global structure with local dynamism: a \textit{Global Semantic Anchor} ensures stylistic stability, while a surgical \textit{Token-Level Affective Adapter} modulates local tension via direct element-wise residual injection. This minimalist design bypasses the bottlenecks of dense attention and architectural cloning, effectively mitigating the overfitting risks associated with data scarcity. Experiments demonstrate that NarraScore achieves state-of-the-art consistency and narrative alignment with negligible computational overhead, establishing a fully autonomous paradigm for long-video soundtrack generation.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Urban-STA4CLC: Urban Theory-Informed Spatio-Temporal Attention Model for Predicting Post-Disaster Commercial Land Use Change
Aug 12, 2025Natural disasters such as hurricanes and wildfires increasingly introduce unusual disturbance on economic activities, which are especially likely to reshape commercial land use pattern given their sensitive to customer visitation. However, current modeling approaches are limited in capturing such complex interplay between human activities and commercial land use change under and following disturbances. Such interactions have been more effectively captured in current resilient urban planning theories. This study designs and calibrates a Urban Theory-Informed Spatio-Temporal Attention Model for Predicting Post-Disaster Commercial Land Use Change (Urban-STA4CLC) to predict both the yearly decline and expansion of commercial land use at census block level under cumulative impact of disasters on human activities over two years. Guided by urban theories, Urban-STA4CLC integrates both spatial and temporal attention mechanisms with three theory-informed modules. Resilience theory guides a disaster-aware temporal attention module that captures visitation dynamics. Spatial economic theory informs a multi-relational spatial attention module for inter-block representation. Diffusion theory contributes a regularization term that constrains land use transitions. The model performs significantly better than non-theoretical baselines in predicting commercial land use change under the scenario of recurrent hurricanes, with around 19% improvement in F1 score (0.8763). The effectiveness of the theory-guided modules was further validated through ablation studies. The research demonstrates that embedding urban theory into commercial land use modeling models may substantially enhance the capacity to capture its gains and losses. These advances in commercial land use modeling contribute to land use research that accounts for cumulative impacts of recurrent disasters and shifts in economic activity patterns.
Dual-branch PolSAR Image Classification Based on GraphMAE and Local Feature Extraction
Aug 08, 2024


The annotation of polarimetric synthetic aperture radar (PolSAR) images is a labor-intensive and time-consuming process. Therefore, classifying PolSAR images with limited labels is a challenging task in remote sensing domain. In recent years, self-supervised learning approaches have proven effective in PolSAR image classification with sparse labels. However, we observe a lack of research on generative selfsupervised learning in the studied task. Motivated by this, we propose a dual-branch classification model based on generative self-supervised learning in this paper. The first branch is a superpixel-branch, which learns superpixel-level polarimetric representations using a generative self-supervised graph masked autoencoder. To acquire finer classification results, a convolutional neural networks-based pixel-branch is further incorporated to learn pixel-level features. Classification with fused dual-branch features is finally performed to obtain the predictions. Experimental results on the benchmark Flevoland dataset demonstrate that our approach yields promising classification results.
PRTGS: Precomputed Radiance Transfer of Gaussian Splats for Real-Time High-Quality Relighting
Aug 07, 2024We proposed Precomputed RadianceTransfer of GaussianSplats (PRTGS), a real-time high-quality relighting method for Gaussian splats in low-frequency lighting environments that captures soft shadows and interreflections by precomputing 3D Gaussian splats' radiance transfer. Existing studies have demonstrated that 3D Gaussian splatting (3DGS) outperforms neural fields' efficiency for dynamic lighting scenarios. However, the current relighting method based on 3DGS still struggles to compute high-quality shadow and indirect illumination in real time for dynamic light, leading to unrealistic rendering results. We solve this problem by precomputing the expensive transport simulations required for complex transfer functions like shadowing, the resulting transfer functions are represented as dense sets of vectors or matrices for every Gaussian splat. We introduce distinct precomputing methods tailored for training and rendering stages, along with unique ray tracing and indirect lighting precomputation techniques for 3D Gaussian splats to accelerate training speed and compute accurate indirect lighting related to environment light. Experimental analyses demonstrate that our approach achieves state-of-the-art visual quality while maintaining competitive training times and allows high-quality real-time (30+ fps) relighting for dynamic light and relatively complex scenes at 1080p resolution.
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024



As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
AI Agent as Urban Planner: Steering Stakeholder Dynamics in Urban Planning via Consensus-based Multi-Agent Reinforcement Learning
Oct 25, 2023In urban planning, land use readjustment plays a pivotal role in aligning land use configurations with the current demands for sustainable urban development. However, present-day urban planning practices face two main issues. Firstly, land use decisions are predominantly dependent on human experts. Besides, while resident engagement in urban planning can promote urban sustainability and livability, it is challenging to reconcile the diverse interests of stakeholders. To address these challenges, we introduce a Consensus-based Multi-Agent Reinforcement Learning framework for real-world land use readjustment. This framework serves participatory urban planning, allowing diverse intelligent agents as stakeholder representatives to vote for preferred land use types. Within this framework, we propose a novel consensus mechanism in reward design to optimize land utilization through collective decision making. To abstract the structure of the complex urban system, the geographic information of cities is transformed into a spatial graph structure and then processed by graph neural networks. Comprehensive experiments on both traditional top-down planning and participatory planning methods from real-world communities indicate that our computational framework enhances global benefits and accommodates diverse interests, leading to improved satisfaction across different demographic groups. By integrating Multi-Agent Reinforcement Learning, our framework ensures that participatory urban planning decisions are more dynamic and adaptive to evolving community needs and provides a robust platform for automating complex real-world urban planning processes.
Exploring Transformer's potential on automatic piano transcription
Apr 08, 2022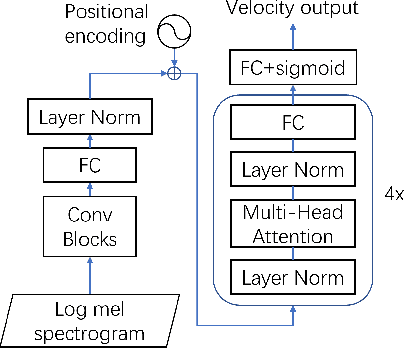

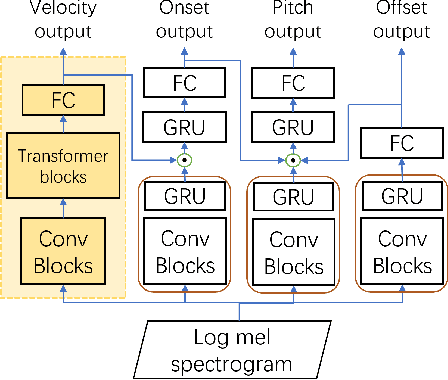
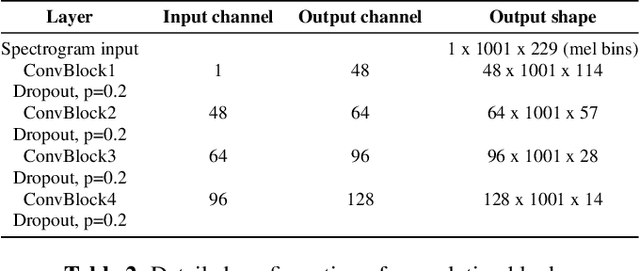
Most recent research about automatic music transcription (AMT) uses convolutional neural networks and recurrent neural networks to model the mapping from music signals to symbolic notation. Based on a high-resolution piano transcription system, we explore the possibility of incorporating another powerful sequence transformation tool -- the Transformer -- to deal with the AMT problem. We argue that the properties of the Transformer make it more suitable for certain AMT subtasks. We confirm the Transformer's superiority on the velocity detection task by experiments on the MAESTRO dataset and a cross-dataset evaluation on the MAPS dataset. We observe a performance improvement on both frame-level and note-level metrics after introducing the Transformer network.